Can’t wait to your new content material to get listed?
Learn why it’s so arduous to estimate how long indexing may take and what you are able to do to hurry issues up.
Indexing is the method of downloading info out of your web site, categorizing it, and storing it in a database. This database – the Google index – is the supply of all info you could find through Google Search.
Pages that aren’t included within the index can not seem in search outcomes, irrespective of how effectively they match a given question.
Let’s assume you’ve lately added a brand new web page to your weblog. In your new submit, you focus on a trending matter, hoping it’ll give you lots of new site visitors.
But earlier than you possibly can see how the web page is doing on Google Search, you need to await it to be listed.
So, how lengthy precisely does this course of take? And when do you have to begin worrying that the dearth of indexing could sign technical issues in your web site?
Let’s examine!
How Long Does Indexing Take? Experts’ Best Guesses
The Google index comprises hundreds of billions of web pages and takes up over 100 million gigabytes of reminiscence.
Additionally, Google doesn’t limit how many pages on a website can be indexed. While some pages could have precedence within the indexing queue, pages usually don’t need to compete for indexing.
There ought to nonetheless be room for another small web page on this colossal database, proper? There’s no want to fret about your weblog entry? Unfortunately, you might need to.
Google admits that not every page processed by its crawlers will be indexed.
In January 2021, Google Search Advocate, John Mueller, elaborated on the subject, disclosing that it’s pretty normal that Google does not index all the pages of a large website.
He defined that the problem for Google is making an attempt to steadiness eager to index as a lot content material as doable with estimating if it will likely be helpful for search engine customers.
Therefore, in lots of instances, not indexing a given piece of content material is Google’s strategic selection.
Google doesn’t need its index to incorporate pages of low quality, duplicate content, or pages unlikely to be seemed for by customers. The greatest solution to hold spam out of search outcomes is to not index it.
But so long as you retain your weblog posts precious and helpful, they’re nonetheless getting listed, proper?
The reply is difficult.
Tomek Rudzki, an indexing skilled at Onely – an organization I work for – calculated that, on common, 16% of precious and indexable pages on well-liked web sites by no means get listed.
Is There A Guarantee That Your Page Will Be Indexed?
As you’ll have already guessed from the title of this text, there isn’t a definitive reply to this indexing query.
You received’t have the ability to set your self a calendar reminder on the day your weblog submit is because of be listed.
But many individuals have requested the identical query earlier than, urging Googlers and skilled search engine marketing professionals to offer some hints.
John Mueller says it can take anywhere from several hours to several weeks for a web page to be listed. He suspects that the majority good content material is picked up and listed inside a couple of week.
Research carried out by Rudzki confirmed that, on common, 83% of pages are listed throughout the first week of publication.
Some pages have to attend as much as eight weeks to get listed. Of course, this solely applies to pages that do get listed finally.
Crawl Demand And Crawl Budget
For a brand new web page in your weblog to be found and listed, Googlebot has to recrawl the weblog.
How typically Googlebot recrawls your web site definitely impacts how rapidly your new web page will get listed, and that will depend on the character of the content material and the frequency with which it will get up to date.
News web sites that publish new content material extraordinarily typically must be recrawled regularly. We can say they’re websites with excessive crawl demand.
An instance of a low crawl demand web site could be a web site concerning the historical past of blacksmithing, as its content material is unlikely to be up to date very regularly.
Google mechanically determines whether the site has a low or high crawl demand. During preliminary crawling, it checks what the web site is about and when it was final up to date.
The determination to crawl the positioning kind of typically has nothing to do with the standard of the content material – the decisive issue is the estimated frequency of updates.
The second necessary issue is the crawl rate. It’s the variety of requests Googlebot could make with out overwhelming your server.
If you host your weblog on a low-bandwidth server and Googlebot notices that the server is slowing down, it’ll modify and scale back the crawl charge.
On the opposite hand, if the positioning responds rapidly, the restrict goes up, and Googlebot can crawl extra URLs.
What Needs To Happen Before Your Page Is Indexed?
Since indexing takes time, one can even marvel – how precisely is that point spent?
How is the knowledge out of your web site categorized and included within the Google index?
Let’s focus on the occasions that should occur earlier than the indexing.
Content Discovery
Let’s return to the instance by which you posted a brand new weblog entry. Googlebot wants to find this web page’s URL in step one of the indexing pipeline.
It can occur by:
- Following inner hyperlinks you offered on different pages of your weblog.
- Following exterior hyperlinks created by individuals who discovered your new content material helpful.
- Going via an XML sitemap that you simply uploaded to Google Search Console.
The proven fact that the web page has been found implies that Google is aware of about its existence and URL.
Crawling
Crawling is the method of visiting the URL and fetching the web page’s contents.
While crawling, Googlebot collects details about a given web page’s fundamental matter, what recordsdata this web page comprises, what key phrases seem on it, and so on.
After discovering hyperlinks on a web page, the crawler follows them to the subsequent web page, and the cycle continues.
It’s necessary to keep in mind that Googlebot follows the foundations arrange by robots.txt in order that it received’t crawl pages blocked by the directives you present in that file.
Rendering
The rendering must occur for Googlebot to know each the JavaScript content material and pictures, audio, and video recordsdata.
These sorts of recordsdata at all times have been a much bigger battle for Google than HTML.
Google’s developer advocate, Martin Splitt, compared rendering to cooking a dish.
In this metaphor, the preliminary HTML file of an internet site with hyperlinks to different contents is a recipe. You can press F12 in your keyboard to view it in your browser.
All the web site’s assets, similar to CSS, JavaScript recordsdata, pictures, and movies, are the elements mandatory to offer the web site its remaining look.
When the web site achieves this state, you’re coping with the rendered HTML, extra typically known as Document Object Model.
Martin additionally mentioned that executing JavaScript is the very first rendering stage as a result of JavaScript works like a recipe inside a recipe.
In the not-too-distant previous, Googlebot used to index the preliminary HTML model of a web page and depart JavaScript rendering for late as a result of price and time-consuming nature of the method.
The search engine marketing trade referred to that phenomenon as “the 2 waves of indexing.”
However, now it appears that evidently the 2 waves are not mandatory.
Mueller and Splitt admitted that, these days, nearly every new website goes through the rendering stage by default.
One of Google’s objectives is getting crawling, rendering, and indexing to occur nearer collectively.
Can You Get Your Page Indexed Faster?
You can’t pressure Google to index your new web page.
How rapidly this occurs can be past your management. However, you possibly can optimize your pages in order that discovering and crawling run as easily as doable.
Here’s what you should do:
Make Sure Your Page Is Indexable
There are two necessary guidelines to comply with to maintain your pages indexable:
- You ought to keep away from blocking them by robots.txt or the noindex directive.
- You ought to mark the canonical model of a given content material piece with a canonical tag.
Robots.txt is a file containing directions for robots visiting your web site.
You can use it to specify which crawlers usually are not allowed to go to sure pages or folders. All you need to do is use the disallow directive.
For instance, for those who don’t need robots to go to pages and recordsdata within the folder titled “instance,” your robots.txt file ought to include the next directives:
User-agent: * Disallow: /instance/
Sometimes, it’s doable to dam Googlebot from indexing precious pages by mistake.
If you’re involved that your web page is just not listed resulting from technical issues, it is best to undoubtedly check out your robots.txt.
Googlebot is well mannered and received’t go any web page it was instructed to not to the indexing pipeline. A solution to categorical such a command is to place a noindex directive in:
Make positive that this directive doesn’t seem on pages that needs to be listed.
As we mentioned, Google desires to keep away from indexing duplicate content material. If it finds two pages that appear to be copies of one another, it’ll doubtless solely index one in all them.
The canonical tag was created to keep away from misunderstandings and instantly direct Googlebot to the URL that the web site proprietor considers the unique model of the web page.
Remember that the supply code of a web page you wish to be current within the Google index shouldn’t level to a different web page as canonical.
Submit A Sitemap
A sitemap lists your web site’s each URL that you simply wish to get listed (as much as 50,000).
You can submit it to Google Search Console to assist Google uncover the sitemap extra rapidly.
With a sitemap, you make it simpler for Googlebot to find your pages and enhance the prospect it’ll crawl these it didn’t discover whereas following inner hyperlinks.
It’s a very good follow to reference the sitemap in your robots.txt file.
Ask Google To Recrawl Your Pages
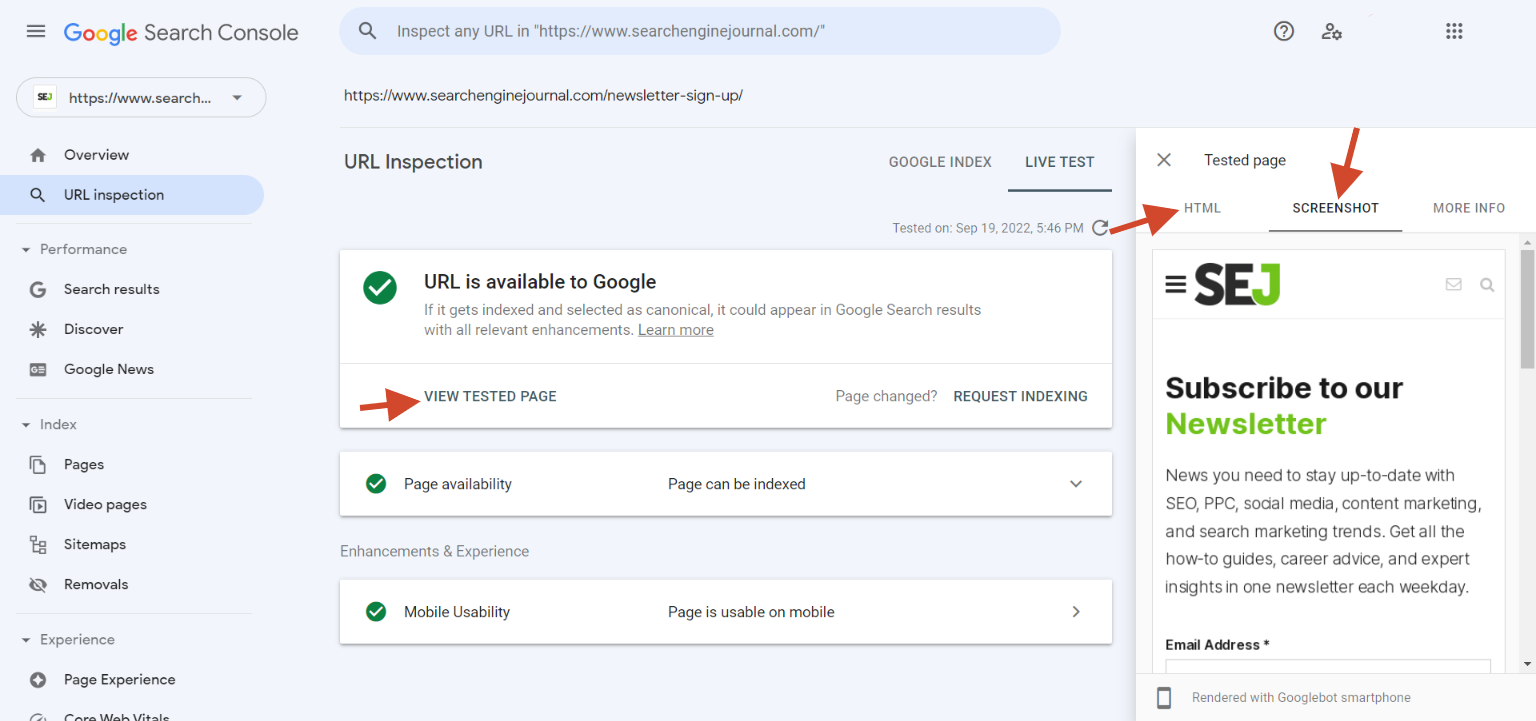
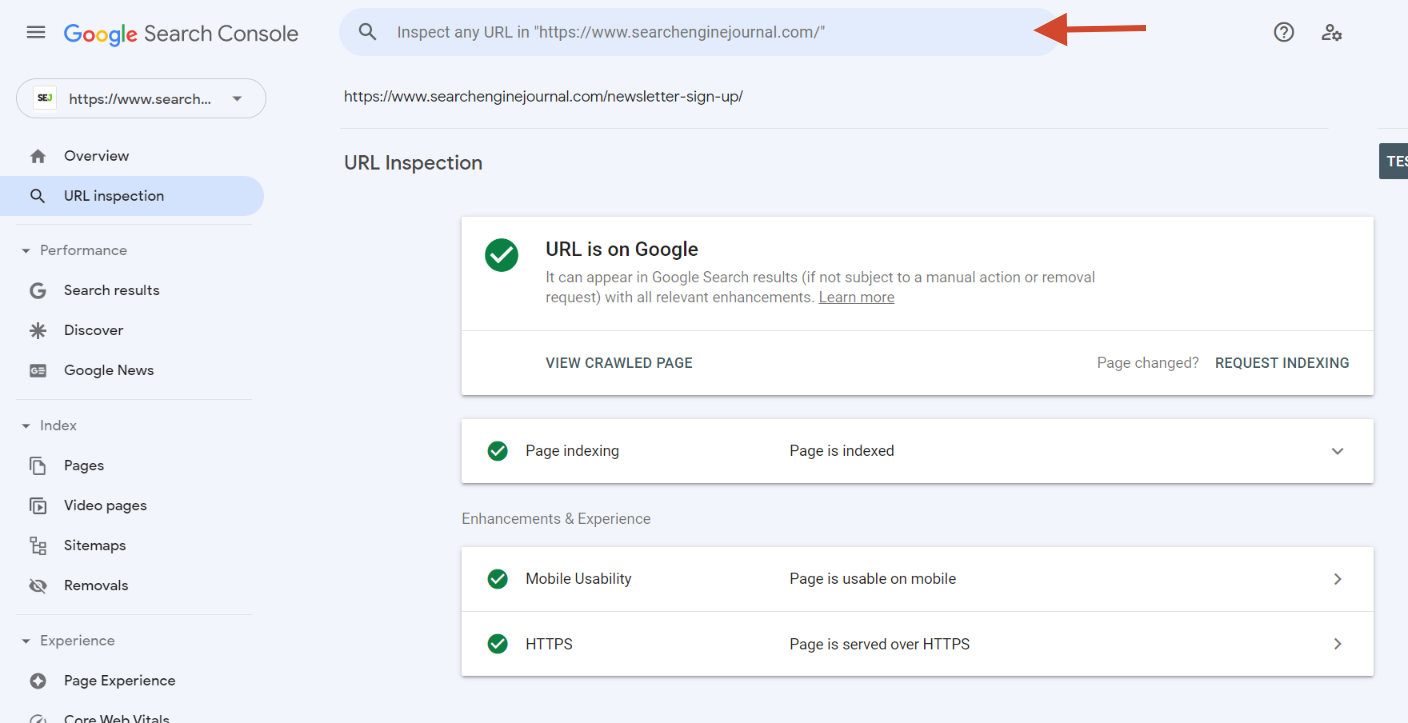 Screenshot from Google Search Console, September 2022
Screenshot from Google Search Console, September 2022You can request a crawl of particular person URLs utilizing the URL Inspection tool out there in Google Search Console.
It nonetheless received’t assure indexing, and also you’ll want some persistence, but it surely’s one other approach to ensure Google is aware of your web page exists.
If Relevant, Use Google’s Indexing API
Indexing API is a instrument permitting you to inform Google about freshly added pages.
Thanks to this instrument, Google can schedule the indexing of time-sensitive content material extra effectively.
Unfortunately, you possibly can’t use it to your weblog posts as a result of, presently, this instrument is meant just for pages with job presents and dwell movies.
While some search engine marketing professionals use the Indexing API for different sorts of pages – and it would work short-term – it’s uncertain to stay a viable answer in the long term.
Prevent The Server Overload On Your Site
Finally, keep in mind to make sure good bandwidth of your server in order that Googlebot doesn’t scale back the crawl charge to your web site.
Avoid utilizing shared internet hosting suppliers, and keep in mind to frequently stress-test your server to ensure it may possibly deal with the job.
Summary
It’s not possible to exactly predict how lengthy it’ll take to your web page to be listed (or whether or not it’ll ever occur) as a result of Google doesn’t index all of the content material it processes.
Typically indexing happens hours to weeks after publication.
The greatest bottleneck for getting listed is getting promptly crawled.
If your content material meets the standard thresholds and there aren’t any technical obstacles for indexing, it is best to primarily take a look at how Googlebot crawls your web site to get contemporary content material listed rapidly.
Before a web page is redirected to the indexing pipeline, Googlebot crawls it and, in lots of instances, renders embed pictures, movies, and JavaScript parts.
Websites that change extra typically and, due to this fact, have the next crawl demand are recrawled extra typically.
When Googlebot visits your web site, it’ll match the crawl charge primarily based on the variety of queries it may possibly ship to your server with out overloading it.
Therefore, it’s value caring for good server bandwidth.
Don’t block Googlebot in robots.txt as a result of then it received’t crawl your pages.
Remember that Google additionally respects the noindex robots meta tag and usually indexes solely the canonical model of the URL.
More assets:
Featured Image: Kristo-Gothard Hunor/Shutterstock
https://www.searchenginejournal.com/how-long-before-google-indexes-my-new-page/464309/